最近大火的AI作画吸引了很多人的目光,AI作画近期取得如此巨大进展的原因个人认为有很大的功劳归属于Stable Diffusion的开源。Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。具体来说,得益于Stability AI的计算资源支持和LAION的数据资源支持,Stable Diffusion在LAION-5B的一个子集上训练了一个Latent Diffusion Models,该模型专门用于文图生成。
Latent Diffusion Models通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火。所以,如果你想了解Stable Diffusion的背后原理,可以跟我一起深入解读一下其背后的论文**High-Resolution Image Synthesis with Latent Diffusion Models(Latent Diffusion Models),**同时这篇文章后续也会针对ppdiffusers的相关代码进行讲解。该论文发表于CVPR2022,第一作者是Robin Rombach,来自德国慕尼黑大学机器视觉与学习研究小组。
再解读论文之前,首先让我深入了解一下Stable Diffusion。
Stable Diffusion基于Latent Diffusion Models,专门用于文图生成任务。目前,Stable Diffusion发布了v1版本,即Stable Diffusion v1,它是Latent Diffusion Models的一个具体实现,具体来说,它特指这样的一个模型架构设置:自动编码器下采样因子为8,UNet大小为860M,文本编码器为CLIP ViT-L/14。官方目前提供了以下权重:
sd-v1-1.ckpt: 237k steps at resolution 256x256 on laion2B-en. 194k steps at resolution 512x512 on laion-high-resolution (170M examples from LAION-5B with resolution >= 1024x1024).sd-v1-2.ckpt: Resumed from sd-v1-1.ckpt. 515k steps at resolution 512x512 on laion-aesthetics v2 5+ (a subset of laion2B-en with estimated aesthetics score > 5.0, and additionally filtered to images with an original size >= 512x512, and an estimated watermark probability < 0.5. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using the LAION-Aesthetics Predictor V2).sd-v1-3.ckpt: Resumed from sd-v1-2.ckpt. 195k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.sd-v1-4.ckpt: Resumed from sd-v1-2.ckpt. 225k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.
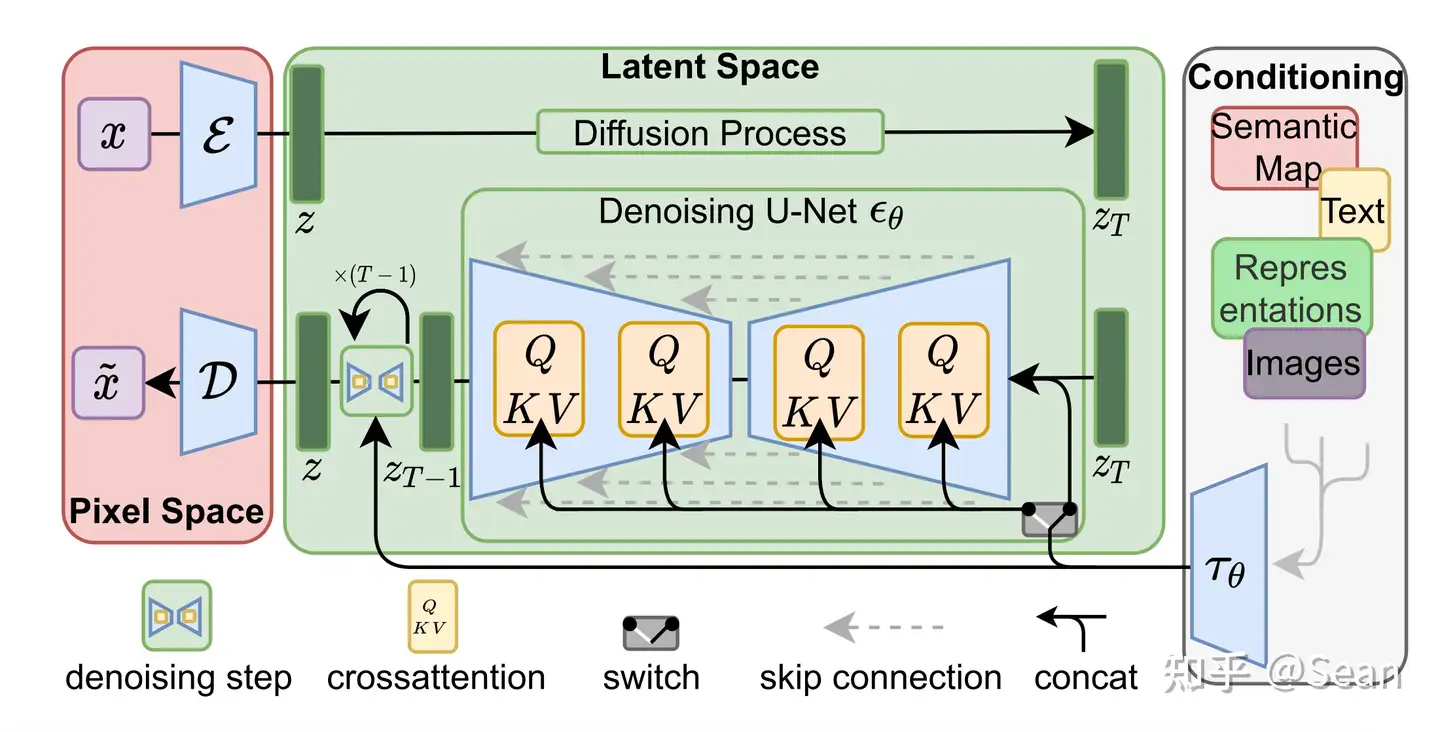
Latent Diffusion Models整体框架如图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 � 和一个解码器 � )。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。个人认为这种将高维特征压缩到低维,然后在低维空间上进行操作的方法具有普适性,可以很容易推广到文本、音频、视频等领域。
在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet。但是有一个重要的地方是论文为diffusion操作引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。