GameLook报道/随着生成型AI技术的能力提升,越来越多的同行开始将注意力放在了通过AI模型提升研发效率上。业内比较火的AI模型有很多,比如画图神器Midjourney、用途多样的Stable Diffusion,以及OpenAI此前刚刚迭代的DALL-E 2,除了后者使用人数有限之外,前两个都有很多的开发者尝试。
不过,对于研发团队而言,尽管Midjourney功能强大且不需要本地安装,但它对于硬件性能的要求较高,甚至同一个指令每次得到的结果都不尽相同。相对而言,功能多、开源、运行速度快,且能耗低内存占用小的Stable Diffusion成为了更理想的选择。
最近,甚至有人用Stable Diffusion和Dreambooth训练出了一个可以模仿人类插画师风格的AI,仅用了32张作品,就训练出了和插画师Hollie Mengert一模一样风格的艺术作品。
目前,训练Stable Diffusion模型的方法主要有四种,它们分别是:Dreambooth、Textual Inversion、LoRA和Hypernetworks。那么,这些模型的特点是什么?哪一个更适合开发者使用呢?
Stable Diffusion训练的四个主流AI模型
Dreambooth
1、DreamBooth是什么?

DreamBooth是谷歌推出的一个主题驱动的AI生成模型,它可以微调文本到图像扩散模型或新图像的结果。Dreambooth可以做一些其他扩散模型不能或者不擅长的事情,比如DALL-E 2、Midjourney以及Stable Diffusion等模型都对主题缺乏情景化。
Dreambooth具备个性化结果的能力,既包括文本到图像模型生成的结果,也包括用户输入的任何图片。
2、Dreambooth的工作原理
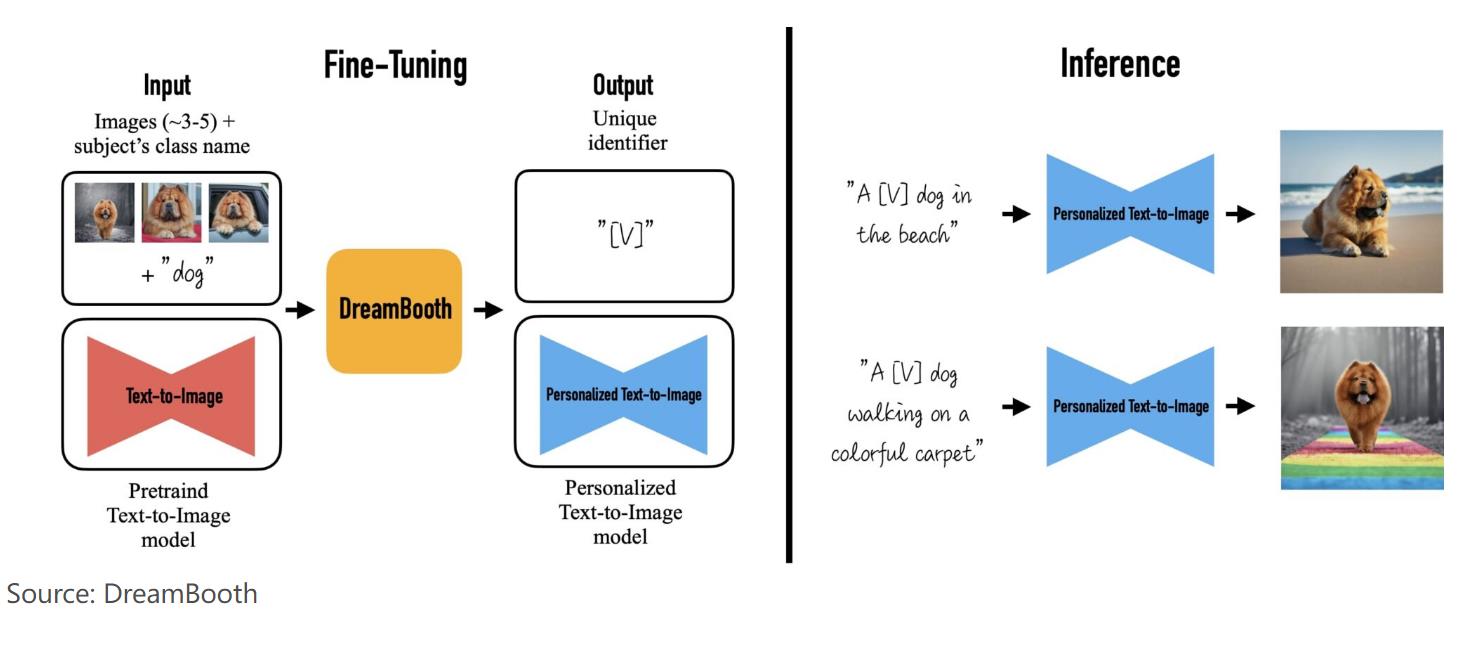
只要有少量图片作为输入(通常3-5张),Dreambooth就可以在调整后的Imagen和其他一些扩散模型的帮助下,生成具有不同背景的基于主题的个性化图像。一旦有图片输入,调整后的Imagen和其他扩散模型就找到唯一标识符,并将其与主题联系起来。在推理时,唯一标识符被用于合成不同上下文中的主题。
3、使用方法:
1)准备输入图片:如果想将你自己变成AI美术,最少准备五张清晰的照片,并且按照后续步骤上传至Colab notebook。输入照片越多越好,如果给出的数量较少,那么代码本身就会生成一些输入图片用于训练。
由于上传图片数量不限,所以你可以输入任何数字的图片。拍一些中等尺寸照片和不同角度不同光照的全尺寸照片,另外,不要上传光线较差或者太暗的照片。当然,你也可以用明星照片训练Dreambooth。
2)前往谷歌Colab Notebook:目前,能用Stable Diffusion运行Dreambooth的Colab Notebook有三个:Hugging Face、ShivamShirao和TheLastBen。
考虑到速度问题和pf VRAM的用途,这里我们暂时用TheLastBen Colab notebook训练和生成图片。在你的电脑上打开TheLastBen Colab notebook,点击“File”和“Save a copy in Drive”。